
今回はPythonの代表的な利用例の一つ、データ分析と機械学習について学んでいきましょう。
統計とデータ分析
現代において、収集したデータを整理、処理、解釈し、有用な情報や洞察を引き出すプロセスはとても重要なものになっています。手軽な手法としてExcelがありますが、複雑なものや大量のデータがある場合はPythonが有効な手段となります。
NumpyとPandas
Pythonでデータ分析といえば、この2つが代表的なものになります。どちらも値を効率的に処理するのに特化したライブラリです。
Numpy
NumPy(Numerical Python)は、数値計算を効率的に行うためのライブラリです。特に、大規模な配列や行列の操作をサポートしており、数学的な関数や線形代数、フーリエ変換などの機能を提供しています。
どのようなことが出来るかを確認していきましょう。前回の仮想環境を起動し、ライブラリをインストールしていきましょう。
pip install numpyそれぞれのサンプルコードを実行していきます。どのような実行結果になるかを確認していきましょう。
import numpy as np
# 1次元配列を作成
a = np.array([1, 2, 3, 4, 5])
print("1次元配列:", a)
# 2次元配列(行列)を作成
b = np.array([[1, 2, 3], [4, 5, 6]])
print("2次元配列:\n", b)
# 配列の形状を確認
print("配列の形状:", b.shape)
# 乱数で配列を作成
random_array = np.random.rand(3, 3) # 3x3のランダムな配列
print("ランダム配列:\n", random_array)
# 行列計算(加算・乗算)
c = np.array([[1, 2], [3, 4]])
d = np.array([[5, 6], [7, 8]])
print("行列の加算:\n", c + d)
print("行列の乗算:\n", np.dot(c, d)) # 行列の積結果としてはこのようになります。Numpy単体では面白味に欠けますが、面白いものを作るためには必ず必要になる縁の下の力持ちなので、使えるようになっていきましょう。
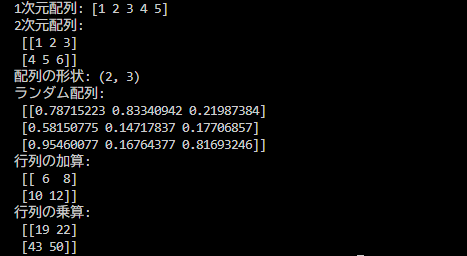
特に行列計算は手計算が面倒で検算も大変なので、これが自動になるとかなり楽になります。
Numpyの配列とpythonの配列の違い
1次元配列の部分に注目すると、Pythonの配列と見た目は変わりません。「ならPythonの配列使えばいいじゃん」となりますが、しっかり違いがあります。
データ型の制約
Pythonの配列(リスト)は異なるデータ型を含むことが出来るのに対し、Numpyの配列は同じ同じデータ型に限ります。これにより、メモリの効率化や計算の高速化を図っています。
my_list = [1, 2.5, 'hello']import numpy as np
my_array = np.array([1, 2, 3]) # 整数型の配列他にもNumpyはC言語での実装のため計算効率が高く、多次元配列の操作において有利だったりと、通常の配列を使うときよりも有利なことが多いです。
Pandas
Pandasは、データ操作や分析を行うためのライブラリで、特に表形式のデータ(データフレーム)を扱うのに適しています。データのクレンジング、変換、集計、可視化などの機能を提供しています。
まずはライブラリをインストールして使えるようにしていきましょう。
pip install pandas次にこのコードを実行してみましょう。配列をデータフレームで表示したり、フィルタリングや列の追加を試してみてください。
import pandas as pd
# サンプルデータを辞書形式で作成
data = {
'名前': ['田中', '鈴木', '佐藤', '山田'],
'年齢': [28, 34, 29, 42],
'職業': ['エンジニア', 'デザイナー', 'マーケティング', 'マネージャー']
}
# データフレームを作成
df = pd.DataFrame(data)
# データフレームの表示
print("データフレーム:")
print(df)
# 年齢の平均を計算
平均年齢 = df['年齢'].mean()
print(f"\n平均年齢: {平均年齢}")
# 年齢が30歳以上の行をフィルタリング
フィルタリング結果 = df[df['年齢'] >= 30]
print("\n年齢が30歳以上の人:")
print(フィルタリング結果)
# 新しい列を追加
df['年齢カテゴリ'] = ['若年層' if age < 30 else '中年層' for age in df['年齢']]
print("\n新しい列を追加したデータフレーム:")
print(df)pd.DataFrameで配列をデータフレーム化できます。printすると、一番左の列が行数が入ります。
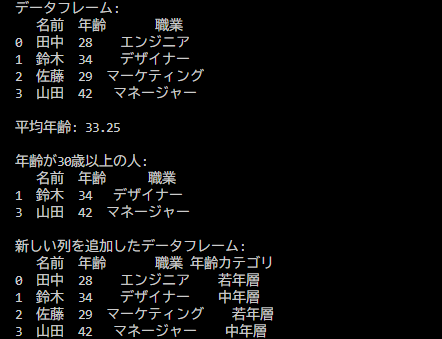
余談ですが、今回のコードでは日本語(厳密にはマルチバイト文字)を変数として宣言していますが、正常に動作しています。PythonやJavaScriptなどではこれができます。ただし、予期しないエラーや可読性の低下につながるので、できるんだ程度に覚えておいてください。よくネタソースコードで用いられるテクニックです。
もう少し実践的な内容にしてみましょう。以下のcsvをcustomers.csvという名前で保存してください。
ID,名前,性別,年齢,住所,登録日
1,山田太郎,男性,30,東京都新宿区1-1-1,2023-01-15
2,鈴木花子,女性,25,東京都渋谷区2-2-2,2023-02-20
3,佐藤次郎,男性,40,東京都港区3-3-3,2023-03-10
4,田中美咲,女性,28,東京都中央区4-4-4,2023-04-05
5,高橋健一,男性,35,東京都文京区5-5-5,2023-05-15
6,中村優子,女性,32,東京都台東区6-6-6,2023-06-25
7,小林大輔,男性,29,東京都墨田区7-7-7,2023-07-30
8,加藤恵美,女性,27,東京都江東区8-8-8,2023-08-12
9,山本直樹,男性,38,東京都品川区9-9-9,2023-09-18
10,井上真理,女性,31,東京都目黒区10-10-10,2023-10-01
11,松本翔,男性,26,東京都世田谷区11-11-11,2023-01-20
12,渡辺彩,女性,24,東京都杉並区12-12-12,2023-02-15
13,石井健太,男性,41,東京都中野区13-13-13,2023-03-05
14,福田美穂,女性,30,東京都練馬区14-14-14,2023-04-10
15,岡田智子,女性,36,東京都豊島区15-15-15,2023-05-20
16,村上亮,男性,33,東京都北区16-16-16,2023-06-30
17,藤田恵,女性,29,東京都荒川区17-17-17,2023-07-15
18,西村健,男性,37,東京都板橋区18-18-18,2023-08-25
19,長谷川美奈,女性,22,東京都足立区19-19-19,2023-09-10
20,森田翔太,男性,34,東京都葛飾区20-20-20,2023-10-05保存ができたら以下のコードを実行してみましょう。
import pandas as pd
# CSVファイルを読み込む
df = pd.read_csv("customers.csv")
# データの表示
print("データフレームの内容:")
print(df)
# 性別の抽出
male_customers = df[df["性別"] == "男性"]
female_customers = df[df["性別"] == "女性"]
print("\n男性顧客:")
print(male_customers)
print("\n女性顧客:")
print(female_customers)
# 性別ごとのカウント
gender_count = df["性別"].value_counts()
print("\n性別ごとの人数:")
print(gender_count)
# 年齢の平均を計算
average_age = df["年齢"].mean()
print(f"\n年齢の平均: {average_age:.2f}")
# 年齢のフィルタリング(30歳以上)
above_30 = df[df["年齢"] > 30]
print("\n30歳以上の顧客:")
print(above_30)
# 住所でソート
sorted_by_address = df.sort_values(by="住所")
print("\n住所でソートしたデータ:")
print(sorted_by_address)
# 登録日でソート
sorted_by_registration_date = df.sort_values(by="登録日")
print("\n登録日でソートしたデータ:")
print(sorted_by_registration_date)
データフレームにすることで、フィルタリングやソートといった実装が面倒なものもたったの1行で実現できるようになります。
グラフの作成
NumpyとPandasで値の統計処理をするところまでできましたが、結果はコマンドプロンプト上で数値として表示されるのでイマイチ把握しづらいです。ということで可視化してみましょう。
Pythonではグラフとして可視化するためのライブラリが揃っています。今回はMatplotlibとseabornを使ってみましょう。
Matplotlib
Matplotlib(マットプロットリブ)は2Dおよび3Dのグラフを作成することができ、折れ線グラフ、散布図、ヒストグラム、棒グラフ、円グラフなど、さまざまな種類のプロットをサポートしています。
また、グラフのカスタマイズが容易で、色、スタイル、ラベル、タイトル、凡例などを自由に設定できます。
pip install matplotlib手始めに正弦波のグラフを描画してみましょう。こちらのコードをコピーして実行しましょう。ちなみに、matplotlib.pyplotはpltと略されることが多いです。
import matplotlib.pyplot as plt
import numpy as np
# データの準備
x = np.linspace(0, 10, 100) # 0から10までの100個の点
y = np.sin(x) # xの各点に対するsin値
# グラフの作成
plt.figure(figsize=(10, 5)) # グラフのサイズを指定
plt.plot(x, y, label='sin(x)', color='blue') # 折れ線グラフを描画
# グラフの装飾
plt.title('Sine Wave') # タイトル
plt.xlabel('x') # x軸のラベル
plt.ylabel('sin(x)') # y軸のラベル
plt.axhline(0, color='black',linewidth=0.5, ls='--') # x軸
plt.axvline(0, color='black',linewidth=0.5, ls='--') # y軸
plt.grid(color = 'gray', linestyle = '--', linewidth = 0.5) # グリッド
plt.legend() # 凡例の表示
# グラフの表示
plt.show()うまくいくと画像のように新しいウィンドウでグラフが表示されると思います。正弦波がうまく表示されていれば成功です。
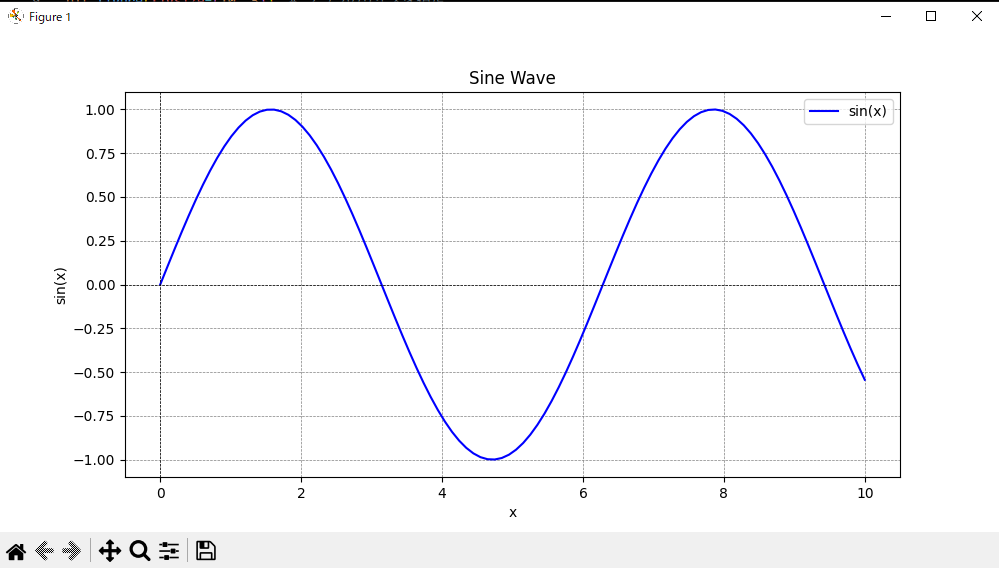
ウィンドウ左下にボタンがあります。それぞれの使い方を見ていきましょう。

左から
- 最初の位置に戻す
- 前の操作に戻す
- 先の操作に送る
- グラフの移動
- 左マウスが上下左右の移動
- 右マウスがズームイン/ズームアウト
- グラフのズームイン/ズームアウト
- 左マウス選択でズームイン
- 右マウス選択でズームアウト
- グラフの余白設定
- グラフを画像として保存
また、×ボタンを押すとPythonの実行が終了し、コードの記述がグラフに反映されるのは実行毎です。
今回のコードで注目するところとして、1つ目がnumpyが数値作成に使われているところがまず挙げられます。0から10までの100等分の値やsinの値は自分で記述しようとすると結構面倒です。
import math
import numpy as np
# xのリストを生成
start = 0
end = 10
num_points = 100
x = [start + (end - start) * i / (num_points - 1) for i in range(num_points)] # 0から10までの100個の点
y = [math.sin(value) for value in x] # 各要素の正弦を計算
# 複雑な記述はいらない!
x = np.linspace(0, 10, 100) # 0から10までの100個の点
y = np.sin(x) # 各要素の正弦を計算2つ目がグラフの装飾です。今回はタイトル、ラベル、軸、グリッド、凡例を変更しましたが、これ以外にもメモリ、線の色、マーカー色、背景色、フォントetc…設定項目は多いです。
お洒落な論文だと装飾のためにExcelではなくてMatplotlibを使っているケースもありますね(AI分野と相性がいいのもある)。
当研究室のことで言及すると、その日ごとの活動量をグラフにプロットするのに利用することがありました。
seaborn
Matplotlibでも十分な機能を有していますが、手が届かないところがいくつかあります。それを補うために開発されたのがseabornになります。例えば、散布図やヒストグラムを作成するのが容易になったり、Pandasとの連携が楽になったりが挙げられます。
物は試しで早速使ってみましょう。
pip install seaborn今回はseabornの組み込みデータセットを利用して、散布図と回帰線を表示してみましょう。seabornはsnsと略されるケースが多いです。
- s: Seabornの最初の文字「S」
- n: Seabornの最後の文字「n」
- s: Seabornの最後の文字「n」の音を引き継いで、可読性を考慮して再度「s」を使用。
らしいです。
import seaborn as sns
import matplotlib.pyplot as plt
# Seabornの組み込みデータセットをロード
tips = sns.load_dataset("tips")
# 散布図を作成
plt.figure(figsize=(10, 6))
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time", style="sex", s=100)
# 回帰線を追加
sns.regplot(data=tips, x="total_bill", y="tip", scatter=False, color='black')
# グラフのタイトルとラベルを設定
plt.title("Total Bill vs Tip")
plt.xlabel("Total Bill ($)")
plt.ylabel("Tip ($)")
plt.legend(title='Time of Day')
plt.grid()
# グラフを表示
plt.show()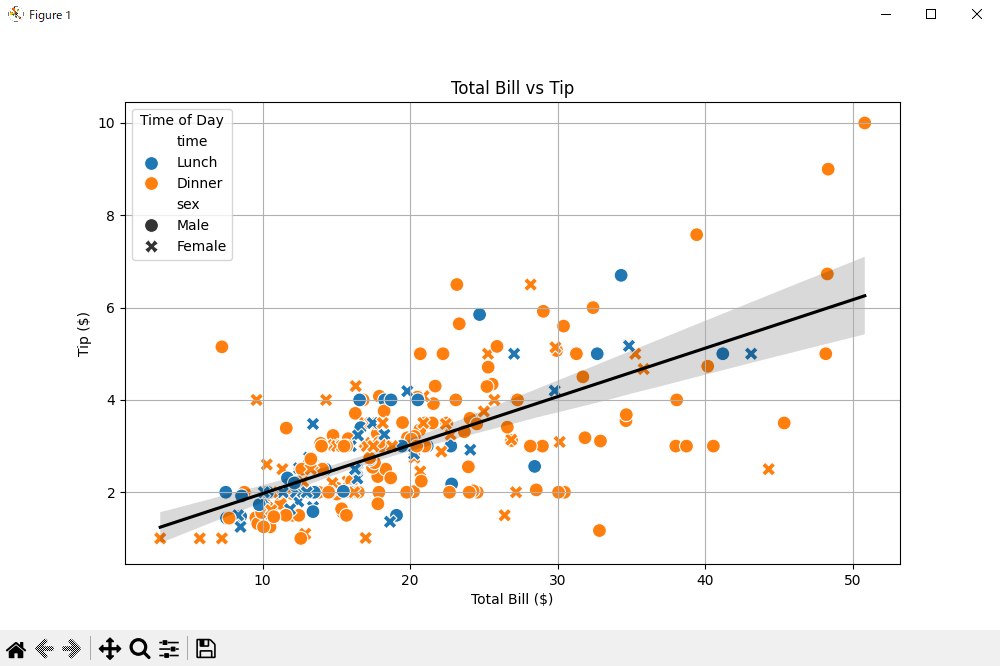
実行結果です。さっきのグラフよりなんか複雑なものが出てきましたね!
グラフの解説をすると、合計金額が高い食事に対しては、チップも高くなる傾向があることを視覚的に示しているものです。点の色が昼食と夕食、点の形が男女になります。黒の線が回帰線で、右上がりなので、相関がある、と判断できるわけですね。
plt.plot()
sns.scatterplot()matplotlibとseabornのどちらもグラフ描写のために用意されているメソッドが20個程度あり、使い分けることで多種多様なグラフを表現できます。特に複雑なものを作成するときはExcelより楽に作れるケースもあります。
実践編
今回は天気を題材にサンプルコードを作成してみました。こんなこともできるのか~と知ってもらう部分と、これは使うから必ず覚えてほしい、という両輪で解説していきます。
長いので折りたたんでいます。展開してコピーしましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
# まずは架空の天気データCSVファイルを作成
def create_weather_csv():
# 日付の範囲を設定(30日分)
dates = pd.date_range(start="2025-03-01", periods=30, freq="D")
# ランダムな天気データを生成
weather_conditions = np.random.choice(
["晴れ", "曇り", "雨", "雪"],
size=30,
p=[0.4, 0.3, 0.2, 0.1], # 各天気の出現確率
)
# 気温データの生成 (10℃〜25℃の範囲)
temp_high = np.round(np.random.uniform(15, 25, 30), 1)
temp_low = np.round(temp_high - np.random.uniform(5, 10, 30), 1)
# 湿度データの生成 (30%〜90%)
humidity = np.round(np.random.uniform(30, 90, 30), 0).astype(int)
# 風速データの生成 (0m/s〜10m/s)
wind_speed = np.round(np.random.uniform(0, 10, 30), 1)
# 降水量データの生成 (雨や雪の日は0mm以上、それ以外は0mm)
precipitation = np.zeros(30)
for i, weather in enumerate(weather_conditions):
if weather in ["雨", "雪"]:
precipitation[i] = np.round(np.random.uniform(0.5, 30, 1)[0], 1)
# データフレームの作成
weather_df = pd.DataFrame(
{
"日付": dates,
"天気": weather_conditions,
"最高気温": temp_high,
"最低気温": temp_low,
"湿度": humidity,
"風速": wind_speed,
"降水量": precipitation,
}
)
# CSVファイルに保存
weather_df.to_csv("weather_data.csv", index=False)
print("天気データCSVファイルを作成しました:weather_data.csv")
return weather_df
# CSVファイルが存在しない場合は作成
if not os.path.exists("weather_data.csv"):
weather_df = create_weather_csv()
else:
# 既存のCSVファイルを読み込む
weather_df = pd.read_csv("weather_data.csv")
# 日付列を日付型に変換
weather_df["日付"] = pd.to_datetime(weather_df["日付"])
print("既存の天気データCSVファイルを読み込みました")
print("\n=== 天気データの基本情報 ===")
print(weather_df.head())
print("\nデータ形状:", weather_df.shape)
print("\nデータ概要:")
print(weather_df.describe())
# データ分析と可視化
print("\n=== 天気データの分析結果 ===")
# 1. 天気の出現回数
weather_counts = weather_df["天気"].value_counts()
print("\n天気の出現回数:")
print(weather_counts)
# 2. 天気別の平均気温
weather_temp_avg = weather_df.groupby("天気")[["最高気温", "最低気温"]].mean()
print("\n天気別の平均気温:")
print(weather_temp_avg)
# 3. 最高気温と最低気温の差の計算(NumPy活用)
weather_df["気温差"] = np.round(weather_df["最高気温"] - weather_df["最低気温"], 1)
print("\n日ごとの気温差の統計:")
print(weather_df["気温差"].describe())
# 4. 相関分析
correlation = weather_df[
["最高気温", "最低気温", "湿度", "風速", "降水量", "気温差"]
].corr()
print("\n相関係数:")
print(correlation)
# 可視化
# プロットのスタイル設定
plt.style.use("seaborn-v0_8")
plt.rcParams["font.family"] = "MS Gothic" # 日本語フォント設定
plt.figure(figsize=(15, 12))
# 1. 天気の出現回数の円グラフ
plt.subplot(2, 2, 1)
plt.pie(weather_counts, labels=weather_counts.index, autopct="%1.1f%%")
plt.title("天気の出現割合")
# 2. 日ごとの最高・最低気温の推移
plt.subplot(2, 2, 2)
plt.plot(weather_df["日付"], weather_df["最高気温"], "r-", label="最高気温")
plt.plot(weather_df["日付"], weather_df["最低気温"], "b-", label="最低気温")
plt.fill_between(
weather_df["日付"], weather_df["最高気温"], weather_df["最低気温"], alpha=0.2
)
plt.title("日ごとの気温推移")
plt.xlabel("日付")
plt.ylabel("気温 (°C)")
plt.xticks(rotation=45)
plt.legend()
# 3. 天気別の平均気温の棒グラフ
plt.subplot(2, 2, 3)
weather_temp_avg.plot(kind="bar", ax=plt.gca())
plt.title("天気別の平均気温")
plt.xlabel("天気")
plt.ylabel("気温 (°C)")
# 4. 降水量と湿度の散布図
plt.subplot(2, 2, 4)
sns.scatterplot(x="降水量", y="湿度", hue="天気", data=weather_df)
plt.title("降水量と湿度の関係")
plt.xlabel("降水量 (mm)")
plt.ylabel("湿度 (%)")
plt.tight_layout()
plt.savefig("weather_analysis.png")
plt.show()
# 高度な分析
# 5. 天気予測モデルを簡易的に作る(前日の気象データから翌日の天気を予測)
print("\n=== 簡易天気予測モデル ===")
# 前日のデータを作成
weather_df["前日_最高気温"] = weather_df["最高気温"].shift(1)
weather_df["前日_最低気温"] = weather_df["最低気温"].shift(1)
weather_df["前日_湿度"] = weather_df["湿度"].shift(1)
weather_df["前日_風速"] = weather_df["風速"].shift(1)
weather_df["前日_降水量"] = weather_df["降水量"].shift(1)
weather_df["前日_天気"] = weather_df["天気"].shift(1)
# NaNを含む行を削除
clean_df = weather_df.dropna()
# 天気の条件ごとに次の日の天気の分布を分析
transition_prob = pd.crosstab(
clean_df["前日_天気"], clean_df["天気"], normalize="index"
)
print("\n天気の遷移確率:")
print(transition_prob)
# 天気別の気象条件の平均値を計算
print("\n天気別の気象条件の平均値:")
weather_conditions_avg = weather_df.groupby("天気")[
["最高気温", "最低気温", "湿度", "風速", "降水量"]
].mean()
print(weather_conditions_avg)
# 週間の集計データ(週ごとの天気パターン)
weather_df["週"] = weather_df["日付"].dt.isocalendar().week
weekly_summary = weather_df.groupby("週").agg(
{
"最高気温": "mean",
"最低気温": "mean",
"湿度": "mean",
"降水量": "sum",
"天気": lambda x: x.value_counts().index[0], # 最も頻度の高い天気
}
)
print("\n週間気象サマリー:")
print(weekly_summary)
# NumPyの高度な機能を使った分析
print("\n=== NumPyを活用した高度な分析 ===")
# 移動平均による気温のトレンド分析
temp_values = weather_df["最高気温"].values
window_size = 3
weights = np.ones(window_size) / window_size
temp_moving_avg = np.convolve(temp_values, weights, mode="valid")
print("\n気温の3日移動平均:")
for i, avg in enumerate(temp_moving_avg[:5]):
print(
f"日付 {weather_df['日付'].iloc[i+window_size-1].strftime('%Y-%m-%d')}: {avg:.1f}°C"
)
# 多項式回帰による気温予測
days = np.arange(len(weather_df))
poly_degree = 2
poly_coef = np.polyfit(days, weather_df["最高気温"].values, poly_degree)
poly_fit = np.polyval(poly_coef, days)
print("\n気温の多項式回帰係数:")
print(poly_coef)
# 気温変動の周波数分析
temp_fft = np.fft.fft(weather_df["最高気温"].values)
temp_freq = np.fft.fftfreq(len(temp_fft))
temp_fft_mag = np.abs(temp_fft)
print("\n気温の周波数分析(上位3成分):")
top_indices = np.argsort(temp_fft_mag)[-3:]
for idx in reversed(top_indices):
if temp_freq[idx] > 0: # 正の周波数のみ表示
print(f"周期: {1/temp_freq[idx]:.1f}日, 強度: {temp_fft_mag[idx]:.1f}")
print("\n分析完了!weather_analysis.pngに可視化結果を保存しました。")
実行すると大きなウィンドウが開き4つのグラフエリアが出てきます。pyファイルと同じディレクトリにCSVファイルと画像が保存されます。
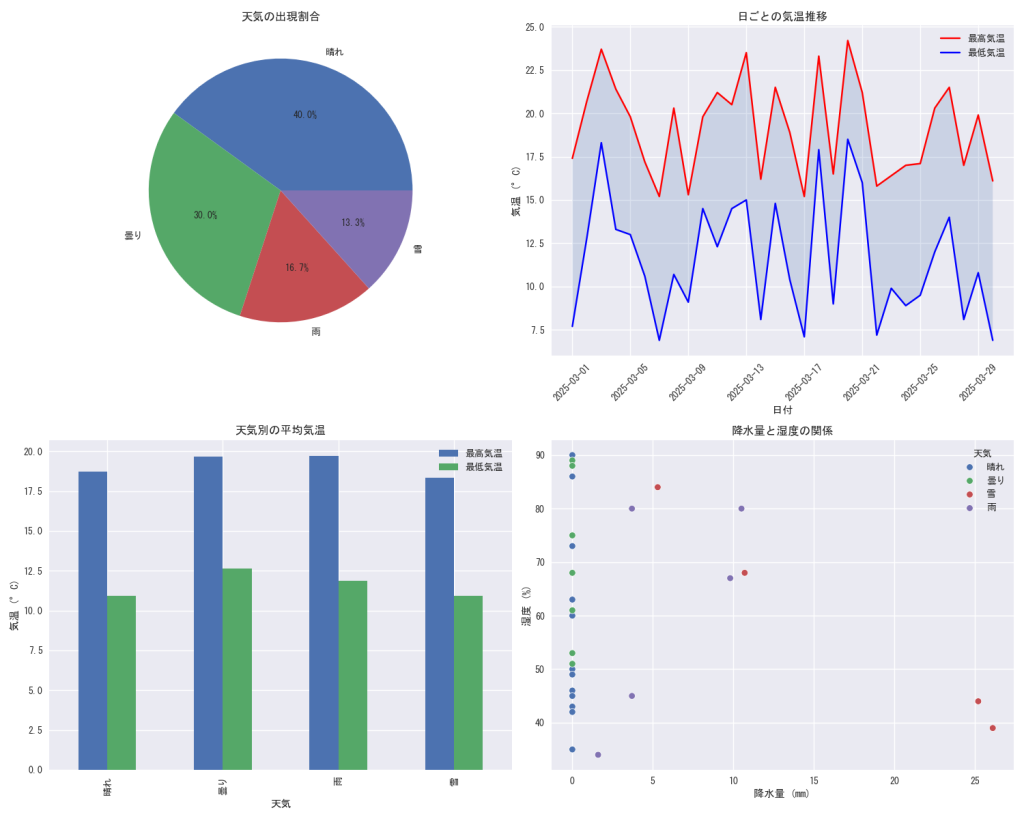
今回解説したライブラリすべてを盛り込んだ内容なので長大に見えますが、やっていることはシンプルです。
まずは分析のために利用する架空の天気データが格納されたCSVファイルを作成しています。すでにCSVがある場合、それを読み込みます。
# まずは架空の天気データCSVファイルを作成
def create_weather_csv():
# 日付の範囲を設定(30日分)
dates = pd.date_range(start="2025-03-01", periods=30, freq="D")
""" 中略 """
# CSVファイルに保存
weather_df.to_csv("weather_data.csv", index=False)
print("天気データCSVファイルを作成しました:weather_data.csv")
return weather_dfそれが終わると、データの分析に移ります。ここで使われているメソッドを確認していきましょう。
print("\n=== 天気データの基本情報 ===")
print(weather_df.head())
""" 中略 """
print("\n相関係数:")
print(correlation)head(): DataFrameの最初の数行を表示するメソッド。shape: DataFrameの行数と列数をタプルで返す属性。describe(): DataFrameの統計的概要を提供するメソッド。value_counts(): 特定の列のユニークな値の出現回数をカウントするメソッド。groupby(): 指定した列に基づいてデータをグループ化するメソッド。mean(): グループ化されたデータの平均を計算するメソッド。round(): 数値を指定した小数点以下の桁数に丸めるメソッド。corr(): DataFrameの列間の相関係数を計算するメソッド。
ここではmean()を覚えておきましょう。比較的使うことが多いです。
次はグラフのプロットになります。
# プロットのスタイル設定
plt.style.use("seaborn-v0_8")
""" 中略 """
plt.savefig("weather_analysis.png")
plt.show()plt.style.use(): Matplotlibのプロットスタイルを設定する関数。plt.rcParams: プロットのフォントやその他の設定を変更するための辞書。plt.figure(): 新しい図を作成する関数。サイズを指定することができる。plt.subplot(): 複数のプロットを1つの図に配置するためのサブプロットを作成する関数。plt.pie(): 円グラフを描画する関数。plt.title(): プロットのタイトルを設定する関数。plt.plot(): 線グラフを描画する関数。plt.fill_between(): 2つの曲線の間を塗りつぶす関数。plt.xlabel(): x軸のラベルを設定する関数。plt.ylabel(): y軸のラベルを設定する関数。plt.xticks(): x軸の目盛りのラベルを設定する関数。plt.legend(): 凡例を表示する関数。plot(): PandasのDataFrameに対して棒グラフを描画するメソッド。sns.scatterplot(): Seabornライブラリを使用して散布図を描画する関数。plt.tight_layout(): プロットのレイアウトを自動調整する関数。plt.savefig(): プロットを画像ファイルとして保存する関数。plt.show(): プロットを表示する関数。
様々な関数やメソッドが用意されていますが、この中で注意しておきたいのが2つあります。1つはplt.rcParamsです。日本語を使用するときには必ずフォントを設定しましょう。
次にplt.savefig()です。今回はplt.show()で新しいウィンドウを展開して結果を確認していますが、実用では画像として保存するケースが多いです。pngの他、jpgやpdfで保存できます。
最後に高度な分析コーナーとしてNumpyを最大限に活用するための例として置いております。ここで使われている関数・メソッドは利用ケースが限られているのでアコーディオンにしておきます。必要な方は確認しておきましょう。
# 5. 天気予測モデルを簡易的に作る(前日の気象データから翌日の天気を予測)
print("\n=== 簡易天気予測モデル ===")
""" 中略 """
if temp_freq[idx] > 0: # 正の周波数のみ表示
print(f"周期: {1/temp_freq[idx]:.1f}日, 強度: {temp_fft_mag[idx]:.1f}")shift(): DataFrameの列を指定した数だけシフト(ずらす)するメソッド。dropna(): NaN(欠損値)を含む行を削除するメソッド。pd.crosstab(): 2つのカテゴリカル変数のクロス集計を行う関数。normalize:pd.crosstab()の引数で、集計結果を正規化するオプション。groupby(): 指定した列に基づいてデータをグループ化するメソッド。mean(): グループ化されたデータの平均を計算するメソッド。agg(): グループ化されたデータに対して複数の集計関数を適用するメソッド。value_counts(): 特定の列のユニークな値の出現回数をカウントするメソッド。dt.isocalendar(): 日付のISOカレンダー情報を取得するメソッド。np.ones(): 指定した形状の配列を1で初期化するNumPy関数。np.convolve(): 2つの配列の畳み込みを計算するNumPy関数。np.polyfit(): 多項式のフィッティングを行うNumPy関数。np.polyval(): 多項式の値を計算するNumPy関数。np.fft.fft(): 高速フーリエ変換を計算するNumPy関数。np.fft.fftfreq(): フーリエ変換の周波数を計算するNumPy関数。np.abs(): 配列の絶対値を計算するNumPy関数。np.argsort(): 配列の要素をソートしたインデックスを返すNumPy関数。
使われている関数などは次のテーマであるAI分野ではそこそこ使われています。AIのアルゴリズムを自分で構築して計算処理をしたい人は調べてみましょう。
人工知能(AI)
統計・データ分析の章でお腹いっぱいだと思いますが、次はAI分野です。2025年現在、AIと言われたら以下の図のような分類ができます。
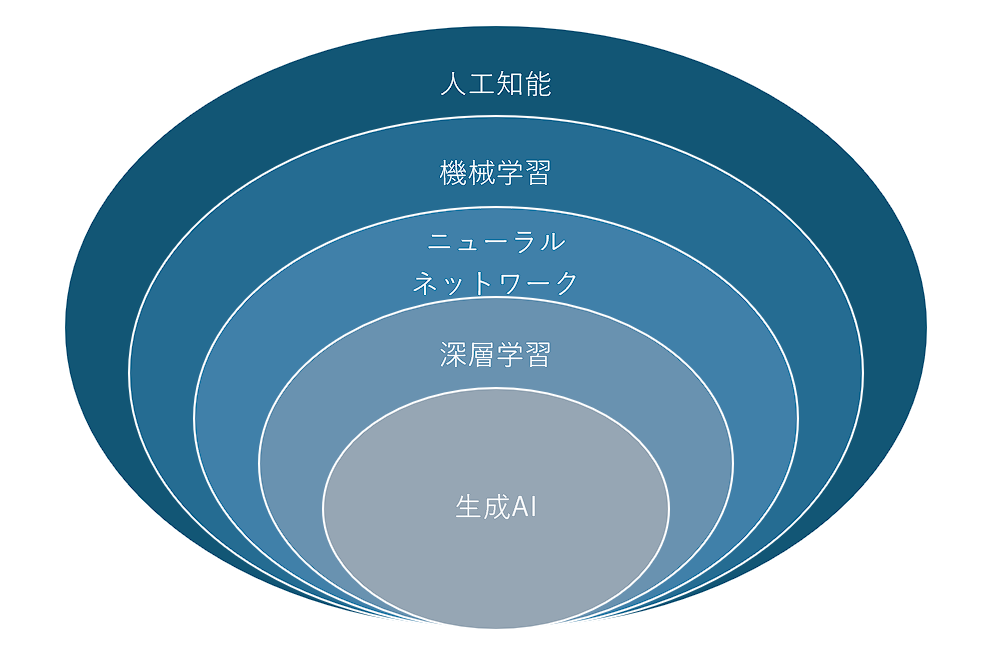
最近はAIと言ったら生成AIに目が行きがちですが、機械学習は工業製品に組み込まれて利用されるケースが多く、需要があります。
当研究室では道路の標識が街路樹などで阻害されていないかを自動判別するための分類器を開発するプロジェクトが進行しています。
PythonとAI
この2つは切っても切れない関係にあると言っても過言ではありません。理由として、ライブラリの存在によるAI構築の工数削減やコミュニティの活発さが挙げられます。ちなみに、処理速度ではC++やJavaに席を譲っています。
今回はAIの利用を体験していきます。とはいっても市井のAIサービスの多くがPythonを使ってサービスを構築しているので、知らずのうちに利用している可能性は大いにありますね。
M-LSD
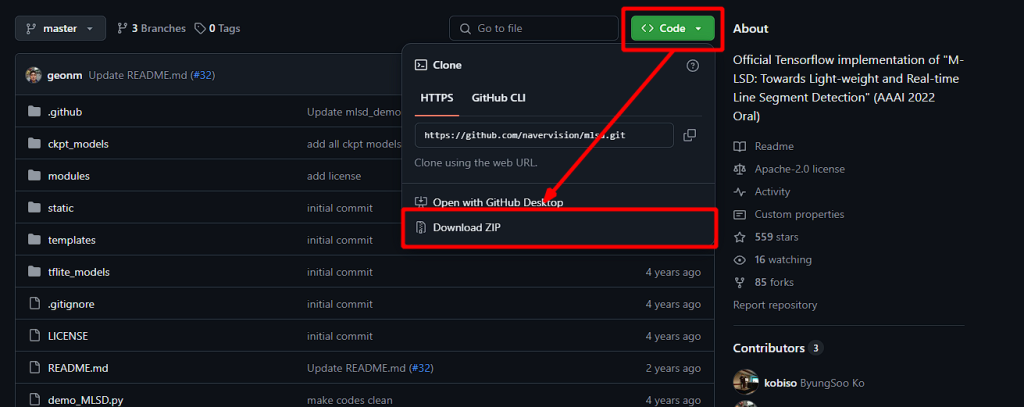
こちらのgithubページを使用します。mlsdと呼ばれる線分検出モデルを使用してみます。Codeをクリックしたのちに、Download ZIPをクリックすると使用するデータを入手しましょう。Gitを使える方はcloneで用意しましょう。
また、そもそもどんなことをするのか確認したい場合は、下記のHugging Faceのページで体験できます。

zipファイルを仮想環境のデータと同じディレクトリで展開します。
その後、必要となるライブラリ群を以下のコマンドでインストールします。このコマンドはmlsdのディレクトリで実行してください。
pip install -r requirements.txtもしこのようなエラーが出る場合はrequirements.txtをこのように修正してください。
ERROR: Invalid requirement: 'tensorflow-gpu=2.3.0': Expected end or semicolon (after name and no valid version specifier)
tensorflow-gpu=2.3.0
^ (from line 4 of requirements.txt)
Hint: = is not a valid operator. Did you mean == ?requirements.txt
numpy
opencv-python
pillow
tensorflow-gpu==2.5.0
Flask
gradioしばらくするとすべてのインストールが終了します。終了したら下記を実行しましょう。
python demo_MLSD.pyこのような内容がコマンドプロンプト上に表示されれば成功です。http://127.0.0.1:5000にアクセスしてみましょう。
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5000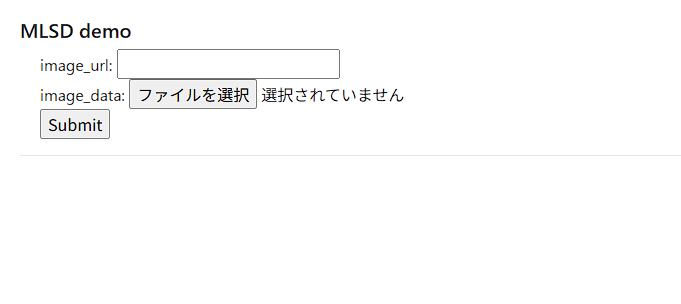
任意の画像のURLかファイル選択でインプットし、Submitボタンを押すと
このような結果が得られます。なんのこっちゃとなるのでそれぞれ説明していきます。
右下がmlsdの線分検出で得られた結果です。これがAIで得られた結果となります。ただ、これでは利用するにはノイズが多いです。そのため、線分の交点をプロット(左下)、四角形になった領域のみプロット(右上)、面積が1番大きい四角形だけを抽出(左上)とすることで望んだ結果を得ます。
利用例としてはドキュメントスキャナが有名です。こちらを利用した場合、これまでの2値化による検出より精度が高く、白色以外の紙も検出できるという利点があります。おそらくですが、googleドライブアプリに搭載されているドキュメントスキャナはmlsdモデルをさらに発展させたTensorFlowモデルを使用しています。

このように、AIと言ってもそこまで利用障壁が高くないものは数多くあります。githubはHugging Faceなどから探して利用してみましょう。また、昨今話題の生成AIはネット上に利用方法が数多く掲載されています。筆者のおすすめはStableDiffusionです。画像処理とAIについての知見を深めるのに有効なので、ぜひ挑戦してみましょう。
まとめ
今回はPythonでも利用のメインストリームにある統計・データ分析、AI分野について取り扱いました。どちらの分野も利用範囲が広くすべて取り扱いきれていない状況ですので、自分が必要な部分は公式リファレンスやgithubなどから情報収集していきましょう。
次回はPythonとWeb開発について取り扱っていきます。こちらも大ボリュームになるので、覚悟して取り組んでいきましょう。
それでは