
前回は構文を一通り紹介しましたが、これだけでは目的のソフトを作ることはできません。ということで今回はライブラリの利用について学んでいきましょう。
import
モジュール/パッケージの読み込みに使う構文です。C言語の#include<stdio.h>に当たります。
import モジュール名こう記述することで、“モジュール名.要素名”の形式でアクセスできるようになります。これは後ほど紹介する標準/外部ライブラリもそうですし、自分が作成したpyファイルも呼び出せます。
import math
print(math.sqrt(16)) # math モジュール内の sqrt 関数を使用
print(math.pi) # math モジュール内の pi 定数を使用また、以下のように記述することで、モジュール全体ではなく一部をインポートすることも可能です。
from モジュール名 import 要素名1, 要素名2, ...この記法だとモジュール名を指定しなくても良くなります。が、名前(関数名)の衝突が起こる可能性が高まるので、やり過ぎには注意。
from math import sqrt, pi
print(sqrt(25))
print(pi)また、以下のように記述することでモジュール名を別名にすることができます。
import モジュール名 as 別名よくあるのがnumpyをnp、pandasをpdと略すケースでしょうか。よく使うものや長い名前だと役にたちます。
標準ライブラリ
特別な操作をしなくても最初から使えるものを紹介していきます。使用頻度はどれも高いです。
ファイルの読み書き
ファイルの書き込み
まずはコピーして実行してみましょう。
with open("example.txt", "w") as f:
f.write("Hello, Python!")うまくいけば同じディレクトリに”example.txt”ができるはずです。そして、テキストファイルには”Hello Python!”と書かれているはずです。確認出来たら、2行目に適当な内容を追記し保存してから閉じましょう。筆者は”welcome to nksg.net”と記述しました。
ファイルの読み込み
with open("example.txt", "r") as f:
content = f.read()
print(content)次にこちらを実行してみましょう。
うまくいくと”Hello Python! 2行目の内容”と出力されるはずです。
$ python .\main.py
Hello, Python!
welcome to nksg.netと共通してwith open~が使われています。
with open("ファイル名", "モード", encoding="文字コード") as ファイルオブジェクト:
# ファイルに対する処理を記述する
# ファイルオブジェクトを使って読み書きを行う- ファイル名: 処理したいファイルのパス(相対パスまたは絶対パス)を指定します。
- モード: ファイルを開く際の操作モードを指定します。以下に主要なモードを挙げます。
- ‘r’ (読み込み – デフォルト): ファイルを読み込み専用で開きます。
- ‘w’ (書き込み): ファイルを書き込み専用で開きます。ファイルが存在する場合は内容が上書きされ、存在しない場合は新しいファイルが作成されます。
- ‘a’ (追記): ファイルを追記専用で開きます。ファイルが存在する場合は末尾に追記され、存在しない場合は新しいファイルが作成されます。
- as ファイルオブジェクト: ファイルを開いた後に、そのファイルへのアクセスを可能にするためのファイルオブジェクトに名前を付けます。この名前を使って、ファイルに対する読み書き操作を行います。fileのfを取って使われるケースが多いです。
- encoding: 文字コードを指定できます。WindowsのデフォルトはCP932です。CP932はだいたい文字化けの原因になるので、utf-8をあらかじめ設定しておくのが無難です。
CSVファイルの読み書き
Excelなどとの連携が便利なことを理由にCSVファイルはよく利用されます。SCVファイルって何?って方は調べてからここに戻ってきましょう。
CSVの書き込み
import csv
data = [["名前", "年齢"], ["太郎", 25], ["次郎", 30]]
with open("data.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(data)とりあえず実行してみましょう。うまくいくと同じディレクトリにCSVファイルができると思います。
CSVの読み込み
import csv
with open("data.csv", "r", encoding="utf-8") as f:
reader = csv.reader(f)
for row in reader:
print(row)こちらを実行すると、各行が出力されるはずです。
新しく出た要素は以下の2つです。これで読み書きができます。
csv.writer(ファイルオブジェクト)
csv.reader(ファイルオブジェクト)JSONの読み書き
ソフトウェア間のやり取りに最近はJSONを使うケースが増えています。JSONって何?という方はまたまた調べてきてください。
JSONの書き込み
import json
data = {"name": "太郎", "age": 25}
with open("data.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=4)こちらもとりあえず実行してみましょう。うまくいくとJSONファイルが出力されるはずです。
JSONの読み込み
import json
with open("data.json", "r", encoding="utf-8") as f:
data = json.load(f)
print(data)新しく出た要素は以下の2つです。dumpの方は少し引数が多いですね。dumpの”ensure_ascii=False”は記述することで非ASCII文字もエスケープされずに保存できます。”indent=4″はインデント文字数です。2でも4でもお好みで。
json.dump(辞書形式の配列, ファイルオブジェクト, ensure_ascii=False, indent=4)
json.load(ファイルオブジェクト)日時と時間
datetimeモジュールを使用すると、現在時刻の取得やフォーマットが可能です。
from datetime import datetime
now = datetime.now()
print("現在時刻:", now)from datetime import datetime
now = datetime.now()
formatted = now.strftime("%Y-%m-%d %H:%M:%S")
print("フォーマット済み日付:", formatted)なんだかんだで時間を取り扱うことは多いです。タイムスタンプやコードの実行時間の計測などなど、時間に関係することが出てきたらdatetimeモジュールは必須です。
正規表現
Pythonは未整形のテキストを扱うことも多いです。そういうときは正規表現を使ってテキストを抽出したり、検索したりしたいはず。re モジュールを使用すると、文字列のパターンマッチングが可能になります。
import re
text = "Python is powerful."
match = re.search(r"powerful", text)
if match:
print("マッチしました!")import re
text = "apple, banana, cherry"
result = re.findall(r"\w+", text)
print(result) # ['apple', 'banana', 'cherry']reはそれ単体で扱いたいぐらいには分量が多いです。今回は使用頻度の高いsearch()とfindall()だけ紹介します。search()は最初に見つかった箇所、findall()は見つかったすべての箇所を返してくれる関数です。

詳しく知りたい場合はこちらが便利です。参照してください。
外部ライブラリ
何か作ろうと思い立ったときコードを書くと思いますが、すべてを自分で開発するのは特別な事情が無い限りやらないほうがいいです。時間は掛かりますし、品質管理も難しいです。
Pythonは外部のライブラリをpipでインストールできます。
pip(Pip Installs Packages)
pip は Python のパッケージ管理システムです。外部のライブラリやパッケージを簡単にインストール、アップグレード、アンインストールするためのツールです。
コマンドの基本形は下記のようになります。どのような機能や引数があるかは”pip -h”で確認することができます。
pip install パッケージ名# 特定のバージョンのパッケージのインストール
pip install <パッケージ名>==<バージョン>
# 最新バージョンへのアップグレード
pip install --upgrade <パッケージ名>
# パッケージのアンインストール
pip uninstall <パッケージ名>
# インストール済みのパッケージの一覧表示
pip listこれらもちょくちょく使うことになるかもしれないです。特に、グローバル環境にライブラリをインストールすると、バージョンの衝突が発生するためです。
バージョン(依存関係)の衝突
Windowsの10と11が別物であるように、Pythonのパッケージのバージョンが変われば全くの別物になります。バージョンの衝突が発生すると、以下のような問題が起こる可能性があります。
ImportError
異なるバージョンのライブラリが競合し、Pythonが適切なバージョンを読み込めずに ImportError が発生します。
# 例: ライブラリAのバージョン1.0と2.0がインストールされている場合
import library_a # どちらのバージョンがインポートされるかは予測不能
# 実行時にエラーが発生するAttributeError
読み込まれたライブラリのバージョンが期待している属性(関数やクラスなど)を持っていない場合に AttributeError が発生します。
# 例: ライブラリBのバージョン1.0では存在する関数が、バージョン2.0では削除されている場合
import library_b
result = library_b.old_function() # バージョン2.0が読み込まれた場合、エラーになる可能性例だとあまり実感が湧かないですが、よくあるのがWeb関連とAIの2つのプロジェクトを同時並行しているケースなどです。前提として使われているライブラリの要求バージョンがそれぞれ違うために、片方のコードが正常に動作しない、みたいなパターンですね。
他にも過去にインストールしたライブラリが古いまま消し忘れて、新しく始めたプロジェクトでうまくコードが実行できない原因がそれだった、とかもあるあるです。
グローバル環境と仮想環境
先述したようなエラーは解決が難しいです。どうしてでしょか。また、どのようにすれば回避できるかを学んでいきましょう。
グローバル環境
グローバル環境とは、コンピュータシステム全体で利用できるPythonのインストール環境のことです。通常、Pythonをインストールすると、このグローバル環境が作成されます。この環境にインストールされたライブラリやパッケージは、システム上のすべてのPythonスクリプトやプロジェクトから利用できます。便利。
仮想環境
仮想環境とは、特定のPythonプロジェクトのために独立した隔離されたPython実行環境を作成する仕組みです。各仮想環境は、独自のPythonバイナリと、そのプロジェクトに必要なライブラリやパッケージのセットを持ちます。
それぞれのメリット/デメリット
| メリット | デメリット | |
|---|---|---|
| グローバル環境 | 手軽、都度インストールしなくても済む | 依存関係の衝突、環境の汚染 |
| 仮想環境 | 管理が容易、再現性の向上、依存関係の分離 | 手間、容量の増加 |
グローバル環境は手軽にインストールできるので楽ですが、不要なライブラリを残したままにすると環境が汚れていきます。仮想環境は最初は手間ですが、管理が楽になります。また、そのプロジェクトが終了した場合、ディレクトリごと消せばリセットできます。
結局どちらを使えばいいの?
「習いたてならグローバル環境でいいよ~」と、言いたいところですが、初心者ほど仮想環境を使ってほしいです。というのも、ミスってもディレクトリを消して再度やり直せばいい環境の方が都合がいいためです。この後始まる外部ライブラリ利用の章では仮想環境を使っていきます。
外部ライブラリの利用 ~スクレイピング編~
お待たせしました、いよいよ外部ライブラリの利用です。今回はスクレイピングを題材にしてみます。
スクレイピングとは
スクレイピングとは、ウェブサイトからデータを自動的に取得する技術です。ただし、サイトの利用規約を確認し、禁止されている場合は行わないようにしましょう。しばしばAIの学習データのために企業がスクレイピングを無断でおこない問題になっています。今後規制や対応が厳しくなると考えられるので、注意しましょう。
仮想環境の構築
まずは先述した仮想環境を構築します。“.venv”の部分は自由に決められます。myenvやkasouなど、自由に付けてもらって構いません。
python -m venv .venvあとは任意のpyファイルを作成してしてください。今回はmain.pyという名前で進めます。
仮想環境のPythonやライブラリを利用するには、仮想環境をアクティブ状態にする必要があります。以下のコードを実行してみましょう。
.venv\Scripts\activate
うまくいくと先頭に(.venv)のような現在使用している仮想環境名が表示されるかと思います。また、仮想環境を終了したい場合は、
deactivateと実行すればOKです。
ライブラリのインストール
スクレイピングで用いられるライブラリは主要なものが3つほどありますが、最初はrequestsを使います。
pip install requestsmain.pyにこのようなコードを記述してみましょう。
import requests
url = "https://example.com"
response = requests.get(url) # example.comにリクエスト
print(response.text)実行すると、HTMLファイルの内容がコマンドプロンプトに表示されるかと思います。
我々人間はブラウザを使って任意のサイトにアクセスしていますが、それをプログラムでも実行できるというわけですね。得られたHTMLファイルのテキストから欲しい情報を抽出して活用するのがスクレイピングの醍醐味になります。
HTMLの解析
さて、前章でHTMLファイルを得られたので、欲しい情報だけを抽出してみましょう。ここで新しくBeautiful Soup 4(bs4)を使ってみたいと思います。
bs4は、Pythonでスクレイピングをする際に非常に便利なライブラリです。HTMLやXMLファイルを解析し、必要な情報を効率的に抽出できます。
pip install beautifulsoup4またまたライブラリをインストールしていきます。作業を完了できたら以下のコードを実行してみましょう。
from bs4 import BeautifulSoup
import requests
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
print(soup.title.text) # タイトルを取得うまくいくと”Example Domain”と出力されるはずです。これはHTMLのtitleタグにあるテキストを抽出するコードです。
<title>Example Domain</title> <-- これがタイトルタグの中身 -->titleタグはHTMLファイルに1つまでですが、pタグなどは複数使用できます。その場合はfind_all()を使用します。
from bs4 import BeautifulSoup
import requests
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
p_texts = [p.text for p in soup.find_all("p")] # pタグの中身を配列に格納
print(p_texts)スクレイピングを学ぶと、勝手にPythonの基本文法とHTMLファイルのタグやDOMの概念を学ぶことができるので、Pythonの勉強には良い題材だと思います。
ブラウザ操作の自動化
Web関連のライブラリをもう一つ紹介したいと思います。seleniumはブラウザ操作を自動化するためのライブラリです。本来の用途は開発したWebサイトの動作テストになりますが、スクレイピングで使用することもできます。ここではなぜrequestよりseleniumが優位なのかは言及しないでおきます。
pip install seleniumseleniumをインストールしていきます。インストール後、以下のコードを実行してみましょう。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get("https://example.com")
print(browser.title)
time.sleep(5) # 5秒待つ
browser.quit()うまくいくと、このようにブラウザが自動に立ち上がり、5秒後に消えると思います。これがseleniumの機能です。
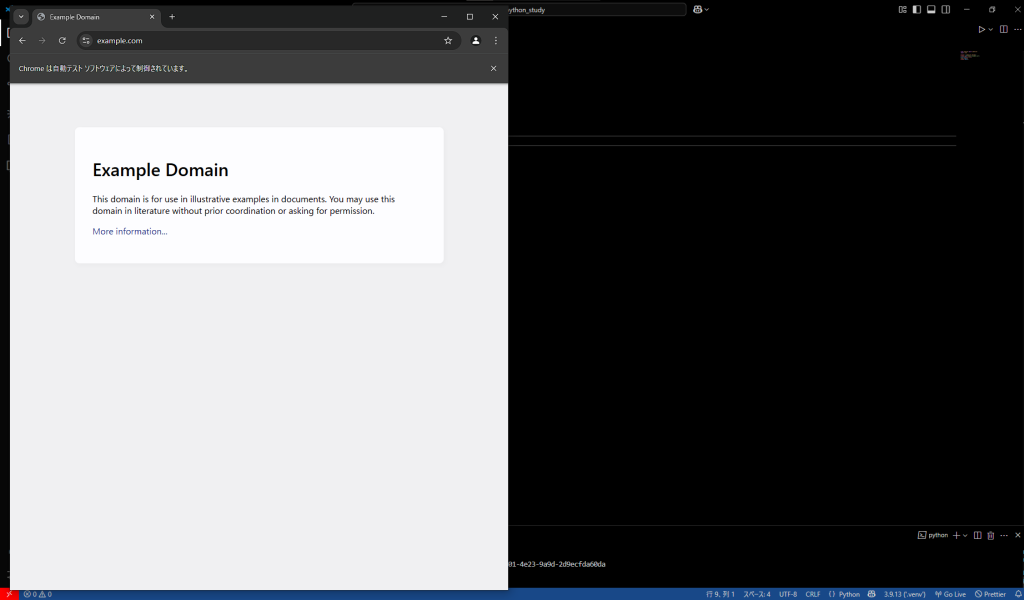
もしうまく動作しない場合はWebDriverが無い可能性があります。「selenium WebDriver」で検索してインストールしてみてください。
ただブラウザを開くだけでは芸が無いので、少し面白いことをしましょう。以下のコードをコピーして実行してみましょう。
from selenium import webdriver
import time
def capture_screenshot(url, filename="screenshot.png"):
"""指定したURLのスクリーンショットを撮影し、保存する"""
driver = webdriver.Chrome()
try:
# URLを開く
driver.get(url)
time.sleep(5)
# スクリーンショットを撮影し、保存
driver.save_screenshot(filename)
print(f"スクリーンショットを '{filename}' に保存しました。")
except Exception as e:
print(f"エラーが発生しました: {e}")
finally:
# WebDriverを終了
driver.quit()
# 実行例
url_to_capture = (
"https://www.shonan-it.ac.jp/" # スクリーンショットを撮りたいウェブページのURL
)
capture_screenshot(url_to_capture)
うまくいくと、スクリーンショットが同じディレクトリに保存されていると思います。

筆者がこのコードを使用した例として、不定期に更新されるサイトの監視に利用しました。更新されたら通知するシステムを開発し、サイトに覗きに行く手間を省くのに寄与しました。
まとめ
今回はライブラリの活用について取り扱いました。使いこなせるとコード記述量の削減や、自動化による恩恵を受けられたりとメリットは大きいのでぜひ勉強していきましょう。
今回使用したrequest、beautifulsoup4、seleniumのリファレンスを置いていきます。この3つは「スクレイピング入門」みたいな単体テーマで取り扱いたいですね。奥が深い分野で楽しいですよ(暗黒微笑)



次回第5回はPythonでWeb開発ということで、3つのライブラリを取り扱いたいと思います。
それでは
おまけ
記事内で「モジュール」「パッケージ」「ライブラリ」を使っているけど、どういうこと?
それぞれについて見ていきましょう。
モジュール
- モジュールは、Pythonのコードが書かれた単一のファイル(.py拡張子)です。
- 関数、クラス、変数などを定義し、特定の機能を提供します。
- 他のPythonプログラムからimport文を使って読み込み、再利用することができます。
- 例:math.py(数学関数)、random.py(乱数生成)
パッケージ
- パッケージは、複数のモジュールをまとめたディレクトリ(フォルダ)です。
- 関連するモジュールを階層的に整理し、名前空間を管理するために使用されます。
- 例:numpy(数値計算)、pandas(データ分析)
ライブラリ
- ライブラリは、複数のモジュールやパッケージの集まりであり、特定の機能を提供します。
- 広範な機能を持つ再利用可能なコードの集合体であり、開発者はライブラリを利用することで効率的にプログラムを開発できます。
- Pythonには、標準ライブラリ(Pythonに組み込まれているライブラリ)と外部ライブラリがあります。
- 例:標準ライブラリのos、外部ライブラリのrequests
図で示してみるとこのようになります。
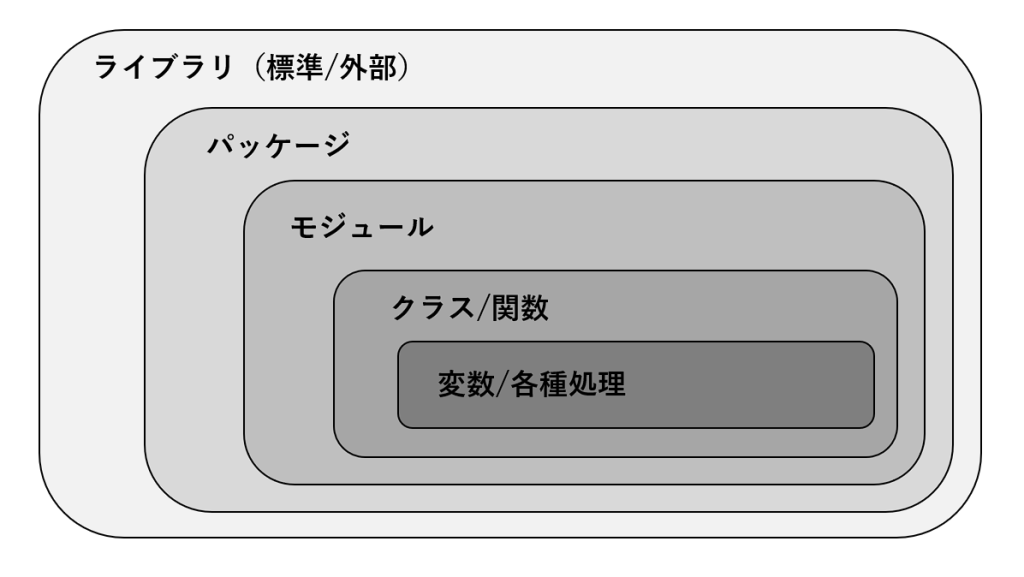
Pythonを利用していて、パッケージとライブラリ、パッケージとモジュールの差異を意識することはあまりないです。ただ、ひとたび間違って覚えてSNSで発言したものならPython警察が現れるので覚えておくに損はありません。